
Catch the Fourth Wave of Coding for a Wild Ride
How to turn LLM's into profit


Many people are familiar with the waves of computing. We started with mainframes, then moved to desktops, and finally ended where we are with mobile and cloud. With each technological shift came accompanying cultural shifts that made vast economic fortunes for the companies who rode each wave.
Fewer are aware of the waves of computer coding that has turned the software engineering from a niche profession few knew about, to something that is taught in elementary school. And now we are about to enter another wave in coding that will change how we interact with machines and usher in a new era of opportunity and chaos. First, some background:
First Wave: Machine Language Programming
The first wave of computer programming began with the development of the first electronic computers in the 1940s. In our first interactions with the machines we created, we spoke their language, wrapping our instructions into ones and zeroes. During this period, programmers used machine language to write code that could be executed directly by the computer's hardware. Programming in machine language was a slow and error-prone process, and only a small number of programmers had the expertise to work with these systems.
Programming was mainly done by scientists, mathematicians, and engineers who were working on specific projects, such as military or scientific research. These programmers often had to develop their own software tools and programming languages, and they were typically highly specialized and had a deep understanding of the hardware and architecture of the machines they were working with.
Riding the first wave generated huge revenues in business applications, including payroll processing, inventory management, and accounting. This powered the growth of business giants like IBM and Fujitsu.

Second Wave: High-Level Language Programming
The second wave of computer programming began in the 1950s with the development of high-level programming languages such as FORTRAN, COBOL, and BASIC. These languages abstracted away many of the low-level details of the machine, making it easier for programmers to write and understand code. They also introduced concepts such as variables, loops, and subroutines that made it possible to write more complex programs.
The second wave really took off in the 1980s with the development of object-oriented programming languages such as Smalltalk and C++. These languages introduced the concept of objects, which encapsulate data and behavior and can be used to build complex software systems.
Programming became a real occupation. The number of computer science graduates in the United States increased from around 6,500 in 1980 to over 42,000 in 1990. Tools started being built for this quickly growing industry. Integrated development environments (IDEs) made it easier to write code, while libraries made it easier to leverage the work of others.
But while programming had become infinitely easier, the way we used computers was still the same. Humans take a problem and try to turn it into computational rules that computers can follow. For instance, a human programmer could program an English to Japanese translator by building a large dictionary of word pairs. Then the programmer would build grammar and syntax rules for how each language worked. Every exception to the rule would have to be another rule, making a good language translation program larger and larger to capture all the intricacies of a language.

This second wave is the foundation that built personal computing, the internet, and mobile phones. Companies like Apple, Netflix and Facebook churn out products because they have armies of software engineers who use these abstracted programming languages to build almost every product we use today.
Third Wave: Machine Learning
Then the internet came, and everything changed. First, we digitized everything ever written. Then we started generating vastly more data than ever existed in human history every week as we blogged about our travels, logged our meals, and took pics of everything.
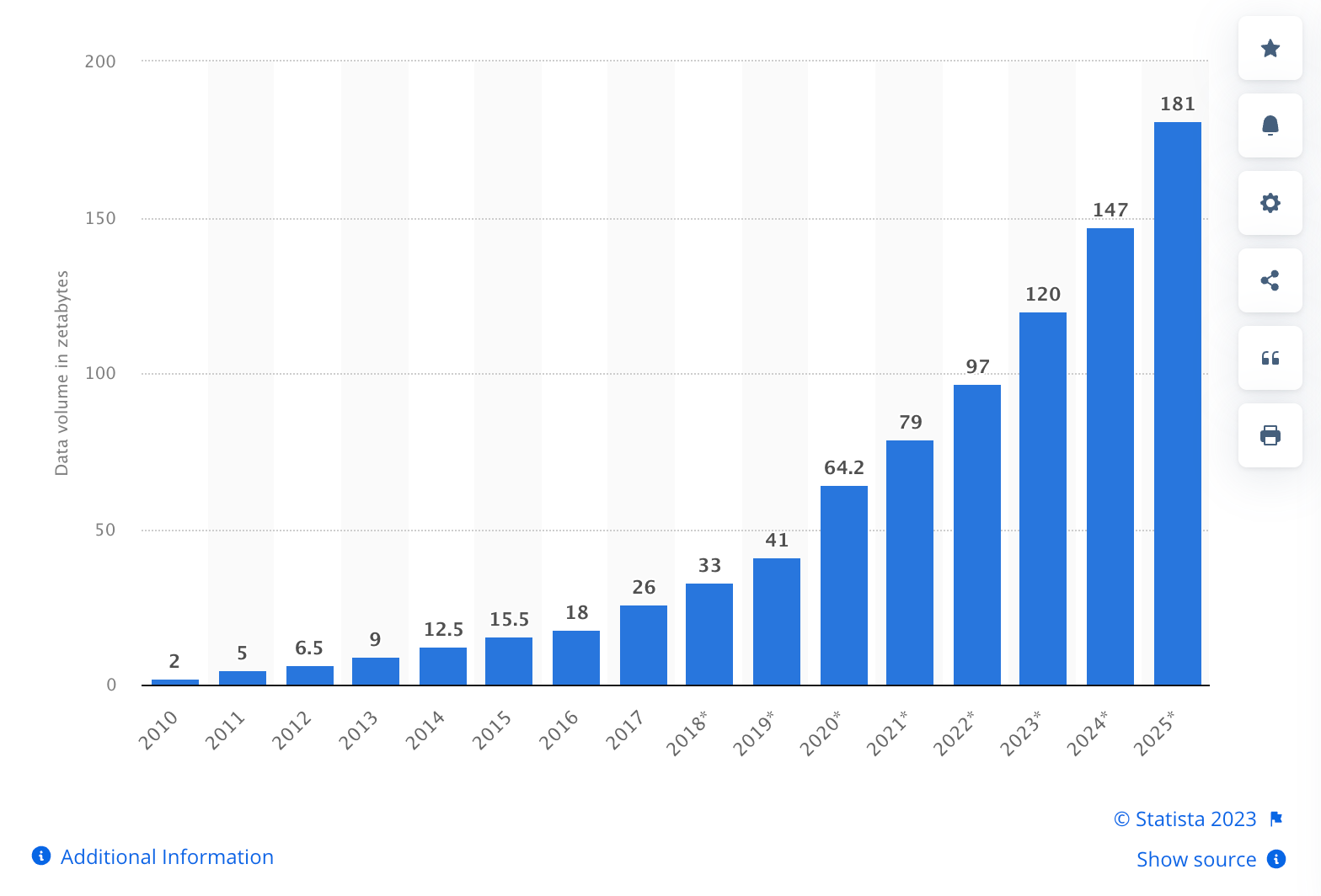
It changed the fabric of human life, but it also changed the world for machines, for they no longer needed humans to write out instructions. With all that data, they could learn for themselves. Enter Machine Learning.
Imagine you're teaching a computer to recognize different types of fruits, like apples, oranges, and bananas. Using Wave Two programing, you could try to program the computer to recognize each fruit by writing out detailed instructions on how to classify each type of fruit (e.g. apples are red). But this becomes super complicated super fast as there are so many exceptions that the set of rules becomes very large and prone to failure.
With Machine Learning, you would approach it in a completely different way. First, you gather a bunch of pictures of different fruits, including apples, oranges, and bananas. You label each picture with the name of the fruit it contains.
Then you feed these pictures into a machine learning algorithm, which analyzes the images and identifies patterns in the data. It’s important to note, that as the programmer, you have no idea what patterns it identifies, and neither does the algorithm.
Once the algorithm has analyzed the data, you can test it by showing it a new picture of a fruit and asking it to identify what kind of fruit it is. If the algorithm is accurate, it should be able to recognize the fruit based on the patterns it has learned from the labeled pictures.
Over time, as you feed the algorithm more data, it becomes better and better at recognizing different types of fruits, and can even start to recognize variations within each type of fruit (assuming you have included that in the labeling).

The important takeaway here is that the programmer and the algorithm no longer have to understand fruit, or languages or whatever they are working on. They only need to have examples; lots and lots of examples.
Overnight, machine learning turned difficult programming challenges (like image recognition) into an ML practice problem that any high schooler taking a free online course can achieve (not much harder than “hello world”).
ML became a commodity as companies started offering free open-source ML libraries. Google’s TensorFlow provides a set of tools and resources for building and training machine learning models, including a flexible architecture that allows users to define and customize their own models.
Machine Learning allowed regular programmers (and non-programmers) to solve really tough computing problems using large amounts of data. But ML is nothing like what people call “General AI”. ML is not going to build terminator robots or turn into your robotic butler. That’s because it requires tons of highly specific data so that it can do highly specific things (like identify cats).
This platform is what is allowing companies like Tesla to build self driving cars, and giants like Google to build voice assistants. And of course ML powers the ad engines that funds social media, video streaming, and every free web service we have come to count on.
Wave 4: Large Language Models (using them, not creating them)
Even while waves 2 and 3 are still going, a fourth wave has just begun to arise. LLM’s are all the rage, and everyone is asking: “How can I cash in?”
First it’s important to understand how LLM’s differ from ML. To be precise, LLM’s are a type of machine learning, but leveraged in a way that has very interesting implications. Typically, you give an ML model a very narrow objective like “Is this a cat or a dog” so that you can give it enough data to be able to answer that question. An LLM’s objective is “Predict the next word” - repeat.
A model with the goal of “speaking openly” requires lots of data and lots of compute. So today’s LLM’s are basically trained on the entire internet. LLM’s have been in development for decades, but they just weren’t very good, until suddenly they were. As access to data and compute power increased, LLM’s crossed a threshold and suddenly became eerily good.
For ML to be useful, you had to train your own specific model. But for every day developers and innovators like you and me, our goal is not to make LLM’s, but to use them. A single LLM like ChatGPT gets trained once and does not get updated for a year or two. But it turns out that you can use “predict the next word” to do a lot more than its originators ever expected. Without the need to train a specific LLM, developers can prompt an existing LLM and get it to do a very wide range of tasks including:
writing articles
writing code in any language
translating text
research summarization
chatbots and customer service
fraud detection
content moderation
natural language processing
Each of the above tasks are pretty broad and traditionally required building and training many specific ML models to try to cover the entire use case. Now, with a few carefully worded prompts, small companies and individuals can accomplish the same or even better.

LLM’s will become a commodity. There is no magic in the architecture (simply layers of neural networks). The differentiation will be in reliability, latency, and access tools. As such, LLM access will become part of general cloud computing and offered up at competitive prices from Google Cloud, Amazon S3, and Microsoft Azure. That’s good news for innovators, as we’ll now have all this powerful compute AND AI at our fingers as an on-demand service.
To take advantage of this wave, small companies can focus on building development teams that are “LLM first”. In the same way that knowledge of assembly language is no longer required, companies will not longer need to commit to javascript or python. High level architects can break down large projects into the necessary components and let LLM’s handle the syntax. This will make coding much cheaper.
The last decade has been about big. Giants like Microsoft, Apple, and Google invested millions of engineer hours to build one-size-fits-all solutions to Search and Maps and other core Apps. With coding becoming cheap, this will usher in an era of personalization and customization. Large companies as well as small startups will be able to build focused solutions for targeted customers. This can help equalize tech, as creating services for under-represented minorities become economically feasible. Now you too, can cheaply build “Uber-for-Kenya”.
Also, expect a new wave of process automation. Tasks for workflows that were not used often enough or had enough training data to build a custom ML model can now be automated through the use of a general purpose LLM. Chatbots can be spun up extremely quickly, bringing top notch customer service to companies that cannot invest in their own technology team.

There will always need to be a bridge between customer needs and technology. With LLM’s on the horizon, being that bridge will require less software development skills and more focus on how to direct an LLM to solve the specific needs of a customer. The space is evolving quickly, but undoubtedly, the access to LLM’s and the tools needed to utilize them will expand rapidly. Riding this wave means being one of the first to radically change the speed and cost of custom software and automation. You can leverage this to optimize your team to build your products faster and cheaper. Or you can bring automation and chatbots to clients for whom this has always been just out of reach.
It’s still early enough to hop on a surfboard and catch this new wave. Who know when the next one will come.